If you’re an organization in Belgium that collects payments, there’s a good chance you’ve heard of CODA or geCOdeerd DAgafschrift files. If not, ask your finance department – trust me, they will know. CODA files are specially formatted bank-statement files you can receive from your bank that contain all the incoming and outgoing transactions of your bank account(s). The structure and format is set out by Febelfin, the Belgian Federation for the Financial sector.
The number of transactions and time-span covered in a single file varies, so the size of one file can be huge. A CODA file uses a format that is difficult for humans to read: fixed-width text format. This makes CODA files hard to reconcile against your expected or pledged transactions in Salesforce. FinDock removes this challenge by reading the files for you. With FinDock, all you have to do is upload your CODA files in your Salesforce Chatter, and we do all the complicated and tedious work for you!
What is the fixed-width text format?
CODA files are fixed-width data files. The rows are arranged in columns, but instead of the columns being separated by a character like a comma or semicolon, every row is the same length, and every column has its own fixed width. While complicated, this format has been around a long time and remains an efficient way to transmit and process large amounts of data. So, your CODA data comes in looking like this:
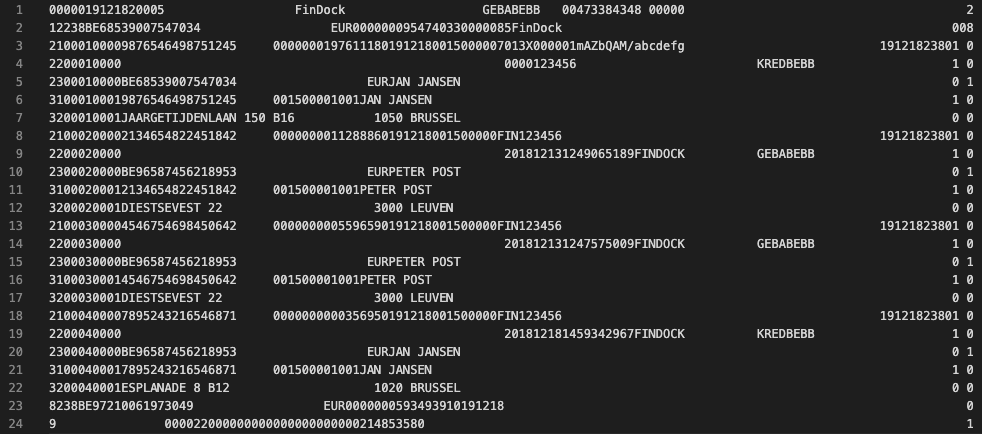
In addition to the fixed widths, this format also supports relationships between columns and rows. What data is available in each column or row can be dynamically determined by the content of previous column(s) and row(s). This means each row in the file can have a different structure, and not every row is a separate transaction.
For Salesforce users, this means that the ‘create-a-CSV-and-upload-with-data-loader’-approach does not work at all. Transforming a CODA file into actionable Salesforce data needs a special approach.
How does FinDock help you?
FinDock reads, extracts and matches the data from CODA files to your Salesforce data for you. The basic flow is as follows:
- You upload your CODA file to FinDock, and our ProcessingHub parses the file into Salesforce data.
- The FinDock out-of-the-box CODA specific logic takes this Salesforce data and extracts it into structured Salesforce fields. For example, in this step relevant dates, transaction type and other information is extracted.
- FinDock then matches each transaction against your existing Salesforce data, updates the status of matched transactions to indicate they have been paid or automatically creates new payments linked to, for example, existing contacts.
- When no match is found, or multiple possible matches are identified, a guided review flow helps you with identifying the right match, split the transaction or book it in any other way.
After this process, the CODA data goes from what we showed above to reconciled Salesforce data like this:
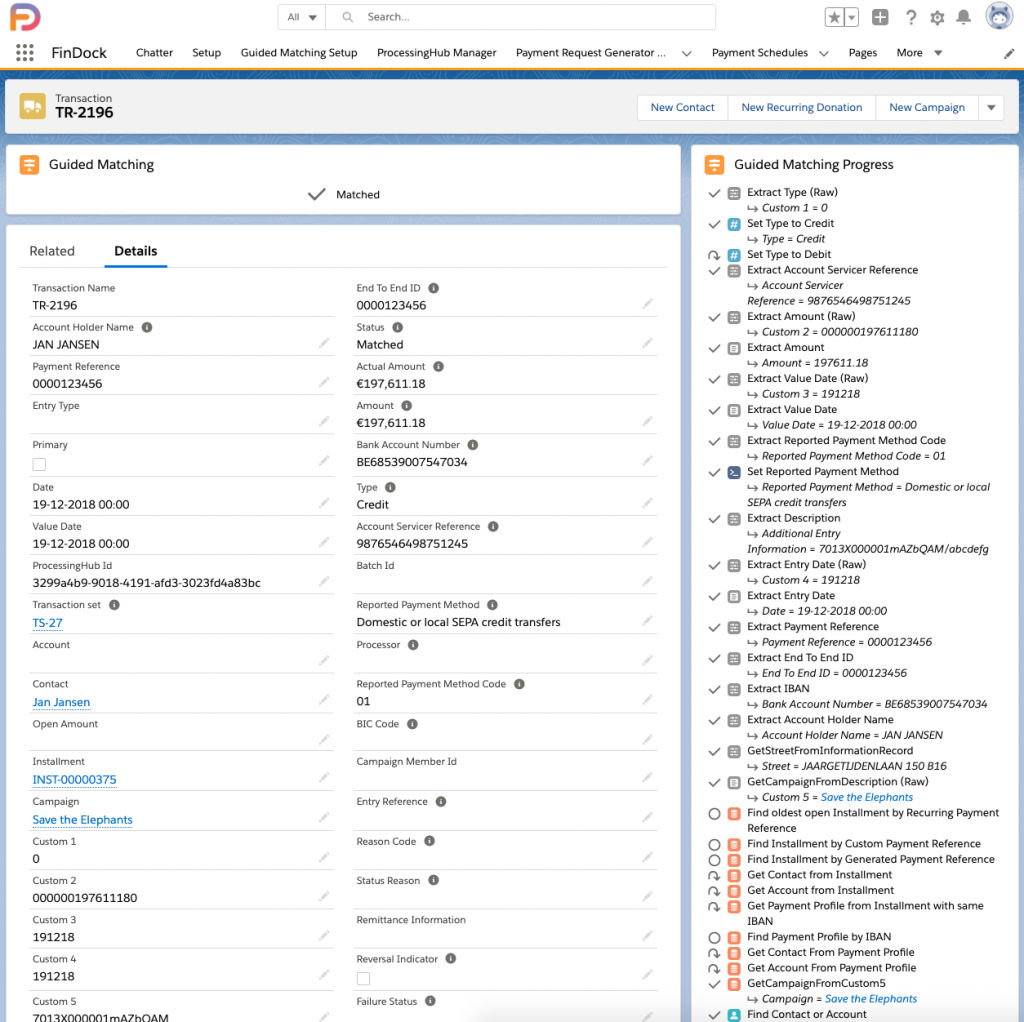
Customize to meet your goals!
You can extend our out-of-the-box CODA parsing logic with our Guided Matching configurable rules to further enrich your CRM data exactly as you want. With your own Guided Matching rules, you can extract specific extra data from your CODA file. But also query, update or create records on top of your own custom, Salesforce data model. And this is all configurable, no coding required.
This way, you will be able to see exactly who has paid you what, why and when, while saving your finance department a lot of time! For more detailed information about CODA and reconciling bank statement files with FinDock, please visit our Knowledge Base.